Walk before you can run, read before you can write
The three ‘R’s of genetics are reading, writing, and arithmetic. Of course, only one of those skills starts with an actual letter ‘R’, but as the arithmetic portion of genetics is often met using a statistical program that happens to be called ‘R’, it’s only ‘writing’ that is the real outlier. Writing stands out in another way, besides being spelled ‘rong. We read a lot of genetic sequence (almost 1.5 trillion bases of whole genome sequence has been read, to date). We use a lot of arithmetic in figuring out what those 1.5 trillion bases are doing. However we have yet to write out a whole animal genome. We change a word here and there in the genetic code, but writing isn’t a skill we’ve mastered in genetics. That could soon change.
Though reading usually follows writing, in genetics it’s the opposite. We can read well, but writing is hard.
In general, things are written before they are read. Even the world’s sacred texts, which you could imagine might arise via supernatural fiat and spontaneously burst into being, didn’t. They were written. God wrote the ten commandments on stone tablets with his finger (pen doesn’t write well on stone, and crayons just melts in his hands). Moses wrote down the first five books (except probably the last bit, where he dies). The Vedas began as an oral tradition, the Koran was transcribed by Muhammad’s disciples, and the entire Star Wars prequel series was simply adlibbed throughout. The closest inversion of the normal order of write-> read is in the book of John, where he says that, “In the beginning was the Word”. But this doesn’t seem to be a word that was actually written somewhere. It just Is. Which certainly saves on paper.
The human genome is an exception, we first read it (that was the Human Genome Project, completed in April of 2003), and we’re now just beginning to talk about writing it.
To be precise, the human genome has been transcribed many times already. Given that each cell in our body has a copy of our genome (except for the red blood cells), and that we each have about 10 trillion cells (not counting those blood cells), and that it’s estimated that about 100 billion people have ever lived on Earth, altogether we can estimate that the human genome has been copied about a trillion trillion times. But no one has ever written it de novo. No one ever sat down and just wrote out the whole thing, with whatever genes, edits or genetic flights of fancy they imagined. From a genetics perspective, writing isn’t really our strong suite.
The story of the writing of our genome involves a lot of time, a lot of duplications, and a lot of mistakes
Our genome had a beginning, of course, but it wasn’t written by us. If we leave to the side the “God wrote Adam’s genome” hypothesis, as our available biblical texts are unclear on the genomic aspects of the creation story, we’re a little hazy on how it all started. The first life on earth began about 4 billion years ago, so it’s not surprising that our understanding of its first steps are still incomplete. We’re very lucky when we find a complete dinosaur fossil, let alone preserved chemical evidence of what life might have been like three billion years earlier than the Brontosaurus. What is known is that your genome came from a mixing of your parents’ genomes, and their genomes came from their parents, and so on and so on. There is an unbroken path of your genome’s journey which traces back to the beginnings of life. This makes placing the blame for any faults or deficiencies in your genetics difficult to pin down on any one person (or ancestral animal).
One idea about the origins of genetics (and life) is that a short RNA polymer was created in the early Earth that could copy itself. RNA, which is chemically very similar to the DNA that comprises our genome, has the additional feature that it can fold into complicated forms, some of which have been found to be able to function like enzymes. Some of these catalytic RNA’s can even copy other RNA’s. It’s possible the first life, and the first genome, were one and the same, a relatively short stretch of RNA that could copy itself.
Admittedly, a short snippet of RNA that happens to be able to copy itself is a long ways from the complexity of us, though it’s a crucial start. But how to get from this ancestral RNA chain, which can’t do anything beyond make copies of itself, to ourselves, all via an unbroken chain of increasingly complex organisms? Through transcription errors, duplications, natural selection, and an intervening several billion years, and we believe you might get us. And every other living thing on Earth, for that matter.
That’s a lot of power to attribute to some copy errors, but four billion years is a long time to accumulate a lot of changes, and mistakes are hard to avoid when writing. Take the bible again, for example. It is supposed, by many, to be inerrant. It is divinely inspired and every aspect of it is true, it is claimed. In other words, no mistakes. Many religionists will concede that this inerrancy likely just applies to the original inspired texts, and that human error could have crept into our current biblical texts. Obviously, however, copy mistakes should be avoided, as introducing error into copies of the bible is probably a special class of blasphemy, and lord knows what the punishment for that would be. Being forced to transcribe the screams of the damned, in longhand, perhaps. Especially wicked people will find the ‘A’ key of their hell-issued typewriter frequently jams, as well.
In fact modern Hebrew owes its vowels and a standardization of pronunciation to efforts to reduce biblical copyist errors. A group of Hebrew scholars in the 6-10th centuries known as the Masoretes created an authoritative text of the Hebrew bible that was later used as the source for many of the Christian translations of the Old Testament. Written Hebrew existed for a over a thousand years without vowels, as they can be inferred from the consonants in a word. However their lack can make some words ambiguous, especially if any of the consonants are smudged. Adding vowels reduces copy error, and so the scribes invention of vowels, as well as other transcription and editing aids all helped ensure their copies contained as few errors as possible. Despite these precautions, however, the Masoretes still made mistakes.
An excellent example is a very brief note on a king of Judah, Jehoiachin. In 2 Chronicles 36:9 we read:
Jehoiachin was eight years old when he began to reign, and he reigned three months and ten days in Jerusalem: and he did that which was evil in the sight of the Lord.
But 2 Kings 24:8 says:
Jehoiachin was eighteen years old when he began to reign, and he reigned in Jerusalem three months. And his mother’s name was Nehushta, the daughter of Elnathan of Jerusalem
In 2 Kings, he’s eighteen: ![]()
While in 2 Chronicles, he’s eight: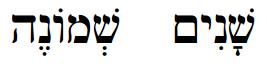
Either there was a copy mistake, and the “ten” got left out of one version, or Jehoiachin was eight and eighteen when we began his reign, each time he reigned for three months. Also, according to the account in 2 Chronicles, he becomes king when he was eight, and furthermore, he “did that which was evil in the sight of the Lord.” As a father of a male child I can attest that it’s definitely possible for an eight year old to do evil in the sight of the lord (though clever eight year olds will endeavor to not do so in the sight of their mother). However it’s probably more in the realm of an eighteen year old to do the kind of acts that would catch the attention of the God of the Old Testament. Those were extreme times, with extra smiting, so you had to have your game on to rise above the basal level of debauchery and corruption. The most likely explanation is a simple copy error. Several more probable errors are known, where, like here, identical information is given in two verses. In other cases, distances or other accounts don’t match what we know of the actual circumstances, and a simple transcription error seems to explain the discrepancy.
Similar mistakes happen to DNA. Sunlight is a big culprit, as UV radiation can cause chemical changes to the DNA bases that makes them impossible to copy. These damaged bases get snipped out by cellular machinery, and are usually repaired correctly, but mistakes happen. Other mechanisms can also cause minor substitutions and deletions to the DNA as well. Over billions of years, these rare changes can add up.
Of course more than just simple substitutions and deletions are needed to add complexity, as these just change the information, but don’t increase it. What’s important, in that regard, are additions to the genome. With our genome’s evolution this probably mostly came about via duplications of stretches of DNA, which can happen relatively easily. Going back to the bible as an analogy, we can see it happened there as well. The first book of Genesis contains two accounts of the creation of man, one in the first chapter, the second in the next chapter. Though thematically similar, they differ in some key details, which causes some trouble for those that insist on a strict grammatical interpretation of the events of the bible. Unlike the multiple ages of wayward Jehoiachin, it’s certain that these two differing accounts of creation weren’t a transcription error. Instead, each story has a different emphasis: the first rendition of the creation story is an account of how the world arose, while the second focuses more on our relation to our world, and to god. The two similar creation stories likely have a shared root in a Mesopotamian story about the creation of the world. However the early priests modified each account to fit the narrative need of the first books of the bible. In other words, a story was duplicated, and then changes to each copy of the story were used to allow the book of Genesis to give a more complex narrative than one copy of the creation story would allow. This method doesn’t just apply to the bible, of course. About half the works of Shakespeare are just variations on the single story-line, ‘Someone’s identity is mistaken, and hilarity ensues’. He just changes the hats around.
It’s worked in a similar manner in our genome. A single gene can have only so many functions. However if a gene happens to be duplicated, each copy can develop in different manners, with different functions. This creates what are known as gene families, sets of very similar genes with similar but distinct roles. For example, an important gene family in humans (and all animals) are the Hox genes, which control some of the first steps in early development of the embryo. We have about 40 different Hox genes, all with different roles in our development, but all probably arose early in the evolutionary history of animals from a single Hox gene.
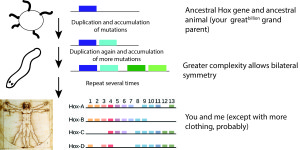
Evolution is powerful, obviously, but also slow. Most investors in a biotech firm hope for returns within a few years, and telling them to wait for a million years, give or take, would be a tough sell (though possibly a refreshing break from the standard slides of projected revenue growth, which invariably shows profits growing exponentially after three years). Hence there is now an effort to create a phase 2 of the genome project, moving from reading to writing. Instead of relying on mutation and selection, we will simple write the genome we want.
The original Human Genome Project was, in retrospect, “HGP:Read”. Phase II could be “HGP:Write”
That was the basis of discussion at a recent meeting, early this month at Harvard Medical School. The original Human Genome Project was about reading the genome. The discussion at this meeting was about a logical extension of this project. Entitled, “HGP-Write: Testing Large Synthetic Genomes in Cells”, the meeting’s goals were to discuss the concept and technology behind rewriting large sections of the genome, or even crafting entire genomes from scratch. The technology to do so doesn’t yet exist. However, our ability to synthesize long stretches of DNA with a specific sequence is rapidly developing, while the cost of doing so decreases. It’s reasonable to speculate that writing a genome will soon be a capability of ours.
The potential applications of the ability to write genomes are several fold. New genetic tools allow us, with relative ease, to make small changes to our genome, as discussed previously. What is being discussed now is the ability to write with complete freedom whatever part of the genome one wishes. The likely starting points would include basic science, rewriting whole sections of the genome would be a quicker route to exploration than piecemeal picking apart at the genes. Industrial applications are easy to imagine as well, as entire metabolic pathways could be reengineered to allow production of a slew of different compounds.
There are, of course, a few ethical considerations involved. For one, this technology would expand our abilities to clone people. Currently cloning a person, which hasn’t yet been done, involves extracting cells from the person to be cloned. With the ability to write a genome, we just need to know the person genetic code, which can be contained in a text file about 1 GB in size (less than DVD), and we can then reconstitute them. If you’re interested in an army of thousands of Jim Watsons, former head of the Human Genome Project, you could do it. Having met Jim I’m confident this is low on the intended uses of HGP:Write, but it’s a formal capability (and if you want to do it, you can find his genome here). For science fiction fans, it solves a problem of long distance colonization of other stars. There is no need for faster than light travel or “generational” ships. Just pack your colonists into a hard drive and reconstitute them on arrival.
Is rewriting our genome similar to rewriting part of the bible, or is it more akin to adding another Harry Potter fan-fiction to the internets?
Furthermore, we’re still grappling with the ethics in making small changes to our genome, and here we are facing the possibility of being able to rewrite entire chromosomes. Our understanding of cellular metabolism and its regulation means that we don’t know enough to really utilize this level of genetic control, but that will likely come soon. What will it mean if we have the ability to add completely novel biochemical pathways to our children? Is our genome akin to an inerrant sacred text, where no changes are allowed? Is it more like a country’s constitution, and changes need to be agreed upon before being written? Or will we approach HGP:write like human genome fan fiction, and every scientist or parent gets to write whatever they see fit? For example, adding chloroplasts to our skin could save on the grocery bill as well as giving us a healthy green complexion. However, it might also lower property values in cloudy cities. Who decides if this is an acceptable addition to human diversity?
Hence there were concerns that this meeting was open to only a hundred attendees, and no reporting to the media of the meeting’s discussion was permitted. This is likely not due to great secrecy about the technology under discussion, an army of clone soldiers to be put under UN auspices was not the agenda of this meeting. Instead it appears that the gag order was due to a scientific journal being given the rights to publish about the meeting, and the attendees acquiescing to their demands for exclusivity. This may show a problem in the way that scientific results, which are often generated with public money, can become in effect the property of the scientific publishers, but that’s an issue for a separate discussion. Nonetheless, it’s probably bad form to keep a meeting on this topic private.
Whether this technology to write our own genomes moves quickly or slowly, it’s clear that we’re quickly learning the basic skills we need to grapple with our genomes. Reading and ‘rithmetic are already well in hand in the field of genetics, and writing will soon be added as well. The only clear fact is that at least we don’t have to worry about arguments over the appropriate fonts to use. In genetics there is no sans-serif or Time New Roman (or Comic Sans). We don’t even have italics or bold. For the conceivable future, at least, we’ll be stuck with just A, C, G, T as we write our genomes.